

“What happens if I need to fuzz something that doesn’t take strings or buffers as inputs” is the question I’ve come to dislike most when talking to people about fuzzing.
Not because it’s a hard question, but because it’s usually the point where fuzzing goes from simple to complicated, with a lot of tricky nooks and crannies that start to matter.
One post can’t tell you everything on the topic, but this post will use Atheris and Python fuzzing to:
- Show a few ways to fuzz structured inputs, while referencing real bugs from the past
- Show how your target or goal should inform your strategy
- Understand limitations of these approaches and how they affect efficiency and effectiveness of fuzzing
We’re going to use JSON as our example because it’s familiar and demonstrates the concept of structure without being overly complicated.
By the end, we’ll see how an idea as simple as “fuzzing something that takes JSON” actually deserves a fair bit of consideration, and also that it’s chock-full of delicious crannies where strange and interesting bugs can hide.
Structured inputs and structure-aware fuzzing#
Targets that take structures or non-string/buffer inputs are common in real code, so techniques for dealing with this have been around for a while, but there seems to be some minor terminology differences depending on who you talk to.
So for the purposes of this post, we’re talking about inputs that have rules about structure that goes beyond basic input types like a buffer and size, or a set of integers.
This could be as simple as “open brackets must always have closing brackets and items must be separated by commas”, and JSON is one of those formats that has simple rules like this.
In fact, all the major rules can be shown in one combined railroad diagram (modified from this nice page that has both visual and textual representation of the JSON format):
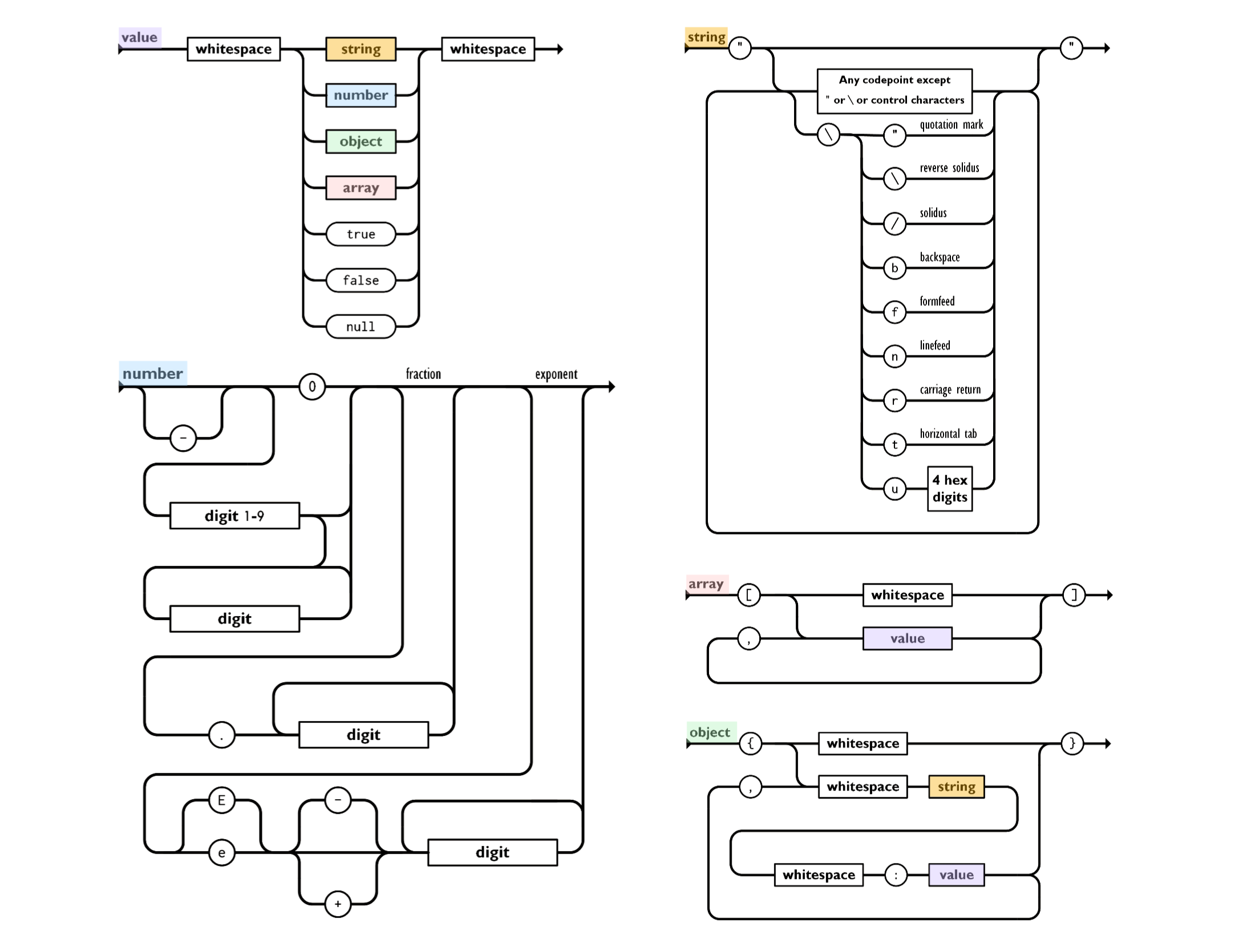
Elements with rounded edges are literals, while squared edges indicate that a rule defines them (yes, I omitted the rules for whitespace and digits).
It could be a lot worse, for example some formats use references, indexes, or offsets that have to stay internally consistent (cough, PDF), but how do we focus on fuzzing so we stay within or near the bounds of what JSON should look like?
We’ll start with an approach known as “structure-aware fuzzing”, because it allows you to define the input programmatically rather than using a specification or grammar.
The basic idea is that the fuzzer generates random inputs, so instead of using inputs directly, we can use them as a source of randomness to generate valid inputs in a probabilistic manner.
This is nice because we can write easily-understood input generation code by picking “randomly”, but we know the same input will always generate the same output. The primary downside is that it creates a layer of indirection since the input is just a bunch of random bytes that need to be interpreted by the harness in order to create the input we feed to the target.
If you’ve been following along with the previous two posts (intro to Atheris and fuzzing for correctness), this might sound a lot like what FuzzedDataProvider, because that is exactly what it does, just wrapped up in a neat little abstraction.
Below is an example of using FuzzedDataProvider to generate json inputs by just picking from lists and using random floats and strings.
def generate_json_value(fdp: atheris.FuzzedDataProvider) -> Any:
"""Top-Level: return an arbitrary valid JSON value/object"""
json_functions = [
generate_object,
generate_array,
generate_number,
generate_string,
generate_literal,
]
generate_func = fdp.PickValueInList(json_functions)
return generate_func(fdp)
def generate_number(fdp: atheris.FuzzedDataProvider) -> float:
return fdp.ConsumeRegularFloat()
def generate_string(fdp: atheris.FuzzedDataProvider) -> str:
return fdp.ConsumeUnicodeNoSurrogates(MAX_STRING_SIZE)
def generate_literal(fdp: atheris.FuzzedDataProvider) -> bool|None:
core_literals = [True, False, None]
return fdp.PickValueInList(core_literals)
def generate_array(fdp: atheris.FuzzedDataProvider) -> list:
member_count = fdp.ConsumeIntInRange(0, MAX_LIST_MEMBERS)
return [generate_json_value(fdp) for _ in range(member_count)]
def generate_object(fdp: atheris.FuzzedDataProvider) -> dict:
member_count = fdp.ConsumeIntInRange(0, MAX_OBJ_MEMBERS)
return {
generate_string(fdp): generate_json_value(fdp)
for _ in range(member_count)
}
This does a nice job of illustrating how you can generate even recursive formats with relatively little code.
Keep in mind this code yields JSON-compatible Python objects instead of strings, so while all of these inputs are valid, they are only a subset of what is possible within the JSON format.
This has the upside of not wasting time on invalid inputs that might be quickly discarded, but it also means it is very unlikely to reach potential corner cases in the parser.
Reaching corners is really what we’re trying to do with fuzzing, but in order to really gauge our effectiveness, we have to first ask what we’re really trying to target.
Strategies for fuzzing structured input targets#
When fuzzing interpreted code like Python, we need to think about what we’re trying to accomplish, because it’s unlikely that memory corruption bugs will just fall out the way they might when fuzzing C/C++ code.
This is also important for structured input targets in general, because usually code that handles complex inputs has one or more stages that reads and validates the input before creating an internal representation and trying to do anything with it, like shown below.
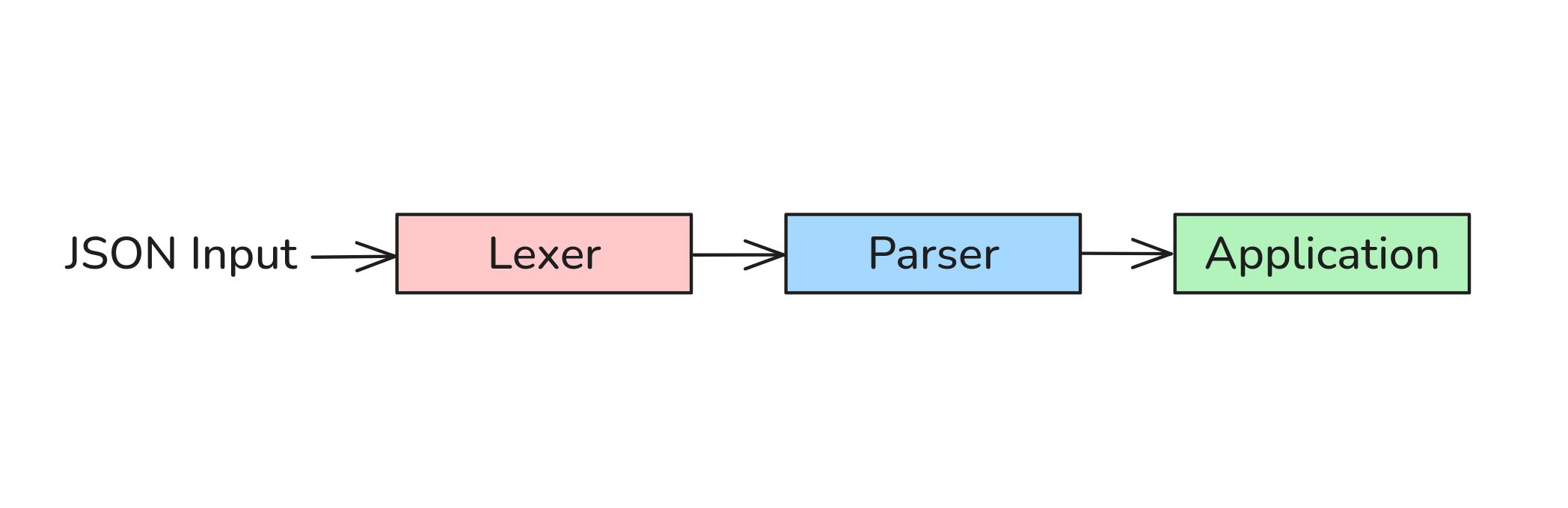
In practice, this means there’s a lot of fast and uninteresting ways for structured inputs to get discarded.
Like with JSON there are only so many characters that a valid input can start with (", {, [, etc), so if the first character of an input isn’t one of these, our target will likely immediately discard the input as invalid without going any further.
So we may want to try to find bugs in all the layers, but often we want to focus on one specific layer since the state space for complex input is combinatorically large and the most efficient strategy is to focus our effort.
Note that this doesn’t mean we don’t want any inputs to be discarded, it just means we want to be purposely targeting the corners that we think are likely to yield interesting bugs.
For example: if an application is using the standard json module to parse input string into an object, we don’t want to spend time throwing invalid inputs that will just get discarded by that module, and we may want to skip JSON parser altogether and just send Python objects like the generation code above allows.
Similarly, if we’re targeting a new third-party JSON library, our fuzzing should be able to generate input strings that can’t be represented as proper Python objects (such as {"foo": 0, "foo": 1}).
Using “fuzzing JSON” as the example, I can think of at least four different target/bug groups that would benefit from different fuzzing approaches:
- Finding logic bugs in an application that takes JSON input, like a web app
- Finding inconsistencies between JSON libraries, where they disagree on what an input parses to
- Finding correctness bugs in a JSON library, where they don’t parse values correctly
- Finding memory safety or parsing bugs in a native implementation written in a language like C that does the heavy lifting for a Python library
Depending on which of these we’re trying to pursue, we should tailor our fuzzing strategy to the bugs we’re trying to find, whether they’re in an application or a library.
Thinking of whether you’re targeting an application or a library will lead us to think more clearly about how to effectively reach corner cases as well as help us see the obstacles we’ll need to overcome.
Fuzzing applications that consume JSON#
Naturally the first approach revolves around how the target application uses JSON input, and we’re more interested in vulnerabilities related to improper input handling and command injections.
In this case, we’re most interested in discovering where our input gets used in order to find injection opportunities or if we can affect program/DB state in unexpected ways.
Since we want to focus on generating inputs in the format the application expects, developing a solid dictionary of strings used by the target would be hugely beneficial, as well as understanding the shape and depth of objects typically used by the application.
Take the following toy-sized vulnerable function, where a properly formed input with a malicious username could cause command injection.
@atheris.instrument_func
def parse_and_use(json_obj_in: Any):
if not isinstance(json_obj_in, dict):
return
if 'usergroup' not in json_obj_in:
return
usergroup = json_obj_in['usergroup']
if usergroup == 'xyz':
username = json_obj_in.get('username')
if username is not None:
# Pretend command injection: checking if a user exists
# ret = os.system(f"ls /home/{usergroup}/{username} >/dev/null 2>&1")
raise Exception('Username reached injection point')
If we instrument only this function with @atheris.instrument_func and use our generate_json_value code from before to generate objects, statistically we’ll never reach the exception.
Why?
Because the fuzzer lacks guidance in the form of coverage or other incentive to generate inputs that will cause it to discover more code. You can tell you’re running into this problem if you look at Atheris output and see something like the following:
$ python fuzz_toy_json.py corpus/
...
INFO: 0 files found in corpus/
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 3 ft: 3 corp: 1/1b exec/s: 0 rss: 37Mb
#3 NEW cov: 4 ft: 4 corp: 2/2b lim: 4 exec/s: 0 rss: 37Mb L: 1/1 MS: 1 ChangeBit-
#524288 pulse cov: 4 ft: 4 corp: 2/2b lim: 4096 exec/s: 262144 rss: 38Mb
#1048576 pulse cov: 4 ft: 4 corp: 2/2b lim: 4096 exec/s: 209715 rss: 38Mb
#2097152 pulse cov: 4 ft: 4 corp: 2/2b lim: 4096 exec/s: 233016 rss: 38Mb
^CKeyboardInterrupt: stopping.
The key feedback is a lack of a lot of NEW lines and the final lines containing ft: 4 and corp: 2/2b, which tells us there are only 4 “features” being covered and that our corpus is only 2 inputs.
This leads us to believe there’s not enough feedback for the fuzzer to get traction, which we could confirm using line coverage, but the corpus size alone makes me guess that the fuzzer generated a non-dictionary input and a dictionary input, and could not pass the check for a key named username.
Let’s check by seeing what gets saved to the corpus…
Where we’ll get a reminder that FuzzedDataProvider inputs are sources of randomness and what the target receives, so it’s good to keep the ability to print out the final input handy.
$ xxd corpus/5ba93c9db0cff93f52b521d7420e43f6eda2784f
00000000: 00 .
$ python fuzz_toy_json.py corpus/5ba93c9db0cff93f52b521d7420e43f6eda2784f 2>/dev/null
DBG: data=b'\x00' -> json_value={}
$ $ xxd corpus/05a79f06cf3f67f726dae68d18a2290f6c9a50c9
00000000: 3a :
$ python fuzz_toy_json.py corpus/05a79f06cf3f67f726dae68d18a2290f6c9a50c9 2>/dev/null
DBG: data=b':' -> json_value=''
There are modern fuzzing approaches that could get past this kind of specific input check, which in Python is commonly string comparisons or membership tests via in or similar, but Atheris doesn’t have these advantages, so we have to work a little.
NOTE: This might be surprising to folks used to AFL++ which has a lot of slick techniques built-in to detect and overcome string comparisons and the like, but these typically leverage knowledge from the compiler.
If we change our JSON string generation function to match the strings our target expects…
def generate_string(fdp: atheris.FuzzedDataProvider) -> str:
# return fdp.ConsumeUnicodeNoSurrogates(MAX_STRING_SIZE)
string_values = ["username", "usergroup", "password", "xyz", "abc"]
return fdp.PickValueInList(string_values)
Then the toy bug pops quickly:
$ python fuzz_toy_json.py corpus/
...
INFO: 0 files found in corpus/
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 3 ft: 3 corp: 1/1b exec/s: 0 rss: 37Mb
#4 NEW cov: 4 ft: 4 corp: 2/2b lim: 4 exec/s: 0 rss: 37Mb L: 1/1 MS: 2 CopyPart-ChangeByte-
#24 NEW cov: 6 ft: 6 corp: 3/5b lim: 4 exec/s: 0 rss: 37Mb L: 3/3 MS: 5 CopyPart-CMP-CopyPart-ShuffleBytes-ChangeByte- DE: "\377\377"-
#60 REDUCE cov: 6 ft: 6 corp: 3/4b lim: 4 exec/s: 0 rss: 37Mb L: 2/2 MS: 1 EraseBytes-
=== Uncaught Python exception: ===
Exception: Username reached injection point
Traceback (most recent call last):
File "/home/user/structure-fuzzing/fuzz_toy_json.py", line 90, in TestOneInput
parse_and_use(json_value)
File "/home/user/structure-fuzzing/fuzz_toy_json.py", line 69, in parse_and_use
Exception: Username reached injection point
==67889== ERROR: libFuzzer: fuzz target exited
SUMMARY: libFuzzer: fuzz target exited
MS: 4 InsertRepeatedBytes-InsertByte-ChangeByte-CopyPart-; base unit: adc83b19e793491b1c6ea0fd8b46cd9f32e592fc
0xe6,0x6c,0x6c,0x40,0x6c,0xa,0x6c,0x6c,0x40,0x6c,0xa,
\346ll@l\012ll@l\012
artifact_prefix='./'; Test unit written to ./crash-3e53035f021ad079d551fed2f81c007721062710
Base64: 5mxsQGwKbGxAbAo=
$ python fuzz_toy_json.py crash-3e53035f021ad079d551fed2f81c007721062710 2>/dev/null
DBG: data=b'\xe6ll@l\nll@l\n' -> json_value={'username': 'xyz', 'xyz': 'username'}
While this was a toy problem, it illustrates the kinds of approaches useful in fuzzing applications that take JSON input:
- Instrument just the part of the target we care about
- Focus on inputs that are likely to discover new functionality in the target
- throw Exceptions or otherwise implement/use bug oracles to indicate notable behavior
Fuzzing JSON Libraries#
In the four approaches we listed above, the latter three can all be considered different ways to target JSON libraries.
You might think that parsing JSON is really simple and that there aren’t interesting bugs other than memory corruption to be found, but you’d be surprised at how tricky parsing JSON can be.
Lucky for us, some Google folks put together a good example of fuzzing the ujson library which includes harnesses illustrating a few different ways that one might fuzz a Python library.
- Differential fuzzer for finding differences between
ujsonandjson - Structured fuzzer for detecting objects that change during an encode/decode round-trip
- Basic string fuzzer designed to be use an instrumented build of the native code to catch memory corruption errors
These are great for reference, so instead of going over their code in depth I’ll just call out some highlights and the kinds of bugs we might look to find with these approaches.
Generating structure inputs with Hypothesis#
One of the things their structured fuzzer demonstrates is using the Python Hypothesis library to generate JSON inputs:
JSON_ATOMS = st.one_of(
st.none(),
st.booleans(),
st.integers(min_value=-(2 ** 63), max_value=2 ** 63 - 1),
st.floats(allow_nan=False, allow_infinity=False),
st.text(),
)
JSON_OBJECTS = st.recursive(
base=JSON_ATOMS,
extend=lambda inner: st.lists(inner) | st.dictionaries(st.text(), inner),
)
UJSON_ENCODE_KWARGS = {
"ensure_ascii": st.booleans(),
"encode_html_chars": st.booleans(),
"escape_forward_slashes": st.booleans(),
"sort_keys": st.booleans(),
"indent": st.integers(0, 20),
}
@given(obj=JSON_OBJECTS, kwargs=st.fixed_dictionaries(UJSON_ENCODE_KWARGS))
def test_ujson_roundtrip(obj, kwargs):
"""Check that all JSON objects round-trip regardless of other options."""
assert obj == ujson.decode(ujson.encode(obj, **kwargs))
I think that Hypothesis is really interesting, and this example demonstrates how it can concisely generate recursive input formats like JSON.
It’s really cool that Hypothesis can interoperate with Atheris, and while I haven’t done a deep-dive to look into performance/efficacy, since all strategies plateau eventually, using multiple strategies leads to better results over time.
As with our FuzzedDataProvider implementation, there’s deliberate decisions on limitations that simplify the code but restrict the inputs via parameters, and is also limited to valid Python values.
When we’re directly targeting the correctness of a library, this could lead to us missing some bugs, so my recommendation would be to supplement this with a fuzzer that “goes the other way” and gives the library strings to parse.
But how do we decide what the correct resulting object is when decoding an arbitrary string to JSON?
The simplest way is to use differential fuzzing.
Detecting JSON issues with differential fuzzing#
If we take a look at the ujson differential fuzzing harness we see a super concise example of differential fuzzing (slightly edited for clarity):
def TestOneInput(input_bytes):
fdp = atheris.FuzzedDataProvider(input_bytes)
original = fdp.ConsumeUnicode(sys.maxsize)
try:
ujson_data = ujson.loads(original)
json_data = json.loads(original)
except Exception as e:
# It would be interesting to enforce that if one of the libraries throws an
# exception, the other does too. However, uJSON accepts many invalid inputs
# that are uninteresting, such as "00". So, that is not done.
return
json_dumped = json.dumps(json_data)
ujson_dumped = json.dumps(ujson_data)
if json_dumped != ujson_dumped:
raise RuntimeError(
"Decoding/encoding disagreement!\nInput: {original}" +
"\n{json_data=}\n{ujson_data=}\n{json_dumped=}\n{ujson_dumped}\n"
)
While this is about as nice as it gets in terms of differential fuzzing, the fastest way to a concise definition of correct behavior is using another library that does the same thing.
And for JSON, having small differences between interpretations is both commonly found and results in real security bugs related to JSON.
A couple of notes on this harness based on notes in the source code and context:
- It is an old harness, the
ujsonlibrary itself is now maintenance-only - This harness exercises a real bug in large number handling that existed when it was written
- It’s designed to be run with the underlying native code instrumented for coverage and the Python fuzzer instrumented with ASAN
That last note is important because coverage is crucial to making this fuzzer effective, because ujson is almost purely native code and ASAN is amazing for finding memory corruption bugs in native code that you’d otherwise miss.
If you didn’t have helpful hints but just ran the Python fuzzer without native instrumentation, you’d see something is up because doing so yields very little coverage and few corpus files.
By using the flag -only_ascii=1 (inherited from libfuzzer) we can avoid irrelevant binary noise and see what happens when we start from an empty corpus:
$ mkdir corpus
$ python json_differential_fuzzer.py -only_ascii=1 corpus/
INFO: Instrumenting json
INFO: Instrumenting json.decoder
INFO: Instrumenting json.scanner
INFO: Instrumenting json.encoder
INFO: Instrumenting decimal
INFO: Instrumenting numbers
INFO: Using built-in libfuzzer
WARNING: Failed to find function "__sanitizer_acquire_crash_state".
WARNING: Failed to find function "__sanitizer_print_stack_trace".
WARNING: Failed to find function "__sanitizer_set_death_callback".
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 4143048641
INFO: 0 files found in corpus/
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 2 ft: 2 corp: 1/1b exec/s: 0 rss: 38Mb
#256 NEW cov: 36 ft: 36 corp: 2/3b lim: 6 exec/s: 0 rss: 38Mb L: 2/2 MS: 4 InsertByte-EraseBytes-CMP-EraseBytes- DE: "\377\377"-
#310 NEW cov: 38 ft: 38 corp: 3/6b lim: 6 exec/s: 0 rss: 38Mb L: 3/3 MS: 4 ChangeASCIIInt-ChangeByte-InsertByte-CrossOver-
#11079 NEW cov: 39 ft: 39 corp: 4/8b lim: 110 exec/s: 0 rss: 38Mb L: 2/3 MS: 4 PersAutoDict-CopyPart-ChangeByte-EraseBytes- DE: "\377\377"-
#39693 NEW cov: 41 ft: 41 corp: 5/11b lim: 389 exec/s: 0 rss: 38Mb L: 3/3 MS: 4 InsertByte-CMP-CopyPart-ChangeBinInt- DE: "\000\000"-
#41233 NEW cov: 42 ft: 42 corp: 6/75b lim: 397 exec/s: 0 rss: 38Mb L: 64/64 MS: 5 InsertRepeatedBytes-CrossOver-InsertByte-ChangeASCIIInt-ChangeBinInt-
#41246 REDUCE cov: 42 ft: 42 corp: 6/46b lim: 397 exec/s: 0 rss: 38Mb L: 35/35 MS: 3 ChangeBit-InsertByte-EraseBytes-
#41258 REDUCE cov: 42 ft: 42 corp: 6/43b lim: 397 exec/s: 0 rss: 38Mb L: 32/32 MS: 2 ChangeBinInt-EraseBytes-
#41400 REDUCE cov: 42 ft: 42 corp: 6/32b lim: 397 exec/s: 0 rss: 38Mb L: 21/21 MS: 2 ChangeByte-EraseBytes-
#41421 REDUCE cov: 42 ft: 42 corp: 6/24b lim: 397 exec/s: 0 rss: 38Mb L: 13/13 MS: 1 EraseBytes-
#41437 REDUCE cov: 42 ft: 42 corp: 6/20b lim: 397 exec/s: 0 rss: 38Mb L: 9/9 MS: 1 EraseBytes-
#42120 REDUCE cov: 42 ft: 42 corp: 6/17b lim: 397 exec/s: 0 rss: 38Mb L: 6/6 MS: 3 PersAutoDict-ChangeBit-EraseBytes- DE: "\000\000"-
#42586 REDUCE cov: 42 ft: 42 corp: 6/16b lim: 397 exec/s: 0 rss: 38Mb L: 5/5 MS: 1 EraseBytes-
#45624 REDUCE cov: 42 ft: 42 corp: 6/15b lim: 421 exec/s: 0 rss: 38Mb L: 4/4 MS: 3 InsertByte-ChangeASCIIInt-EraseBytes-
#524288 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 262144 rss: 38Mb
#1048576 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 262144 rss: 38Mb
#2097152 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 262144 rss: 38Mb
#4194304 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 279620 rss: 39Mb
#8388608 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 262144 rss: 40Mb
#16777216 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 262144 rss: 41Mb
#33554432 pulse cov: 42 ft: 42 corp: 6/15b lim: 4096 exec/s: 264208 rss: 45Mb
^CKeyboardInterrupt: stopping.
The fact that we see Instrumenting json and not Instrumenting usjon in the output is an initial indicator that something might be wrong, since both are imported in a with atheris.instrument_imports(): block.
Inspecting our corpus gives additional clues:
$ for i in corpus/*; do echo $i; xxd $i; echo ""; done
corpus/0fefd27cad4915946049f0352bedc0fa59d601e2
00000000: 2d30 -0
corpus/2e07cf96800a97674c26c0f140da83176fda91c4
00000000: 2d22 22 -""
corpus/dbc0f004854457f59fb16ab863a3a1722cef553f
00000000: 3130 31 101
corpus/e344105f4b462b9bface35924f15a179abdbff81
00000000: 2d22 0922 -"."
corpus/e6a9fc04320a924f46c7c737432bb0389d9dd095
00000000: 2d2d --
The fact that there are not any JSON objects or lists is a good sign that the fuzzer isn’t getting appropriate feedback to differentiate input types.
If we were actually pursuing this target, getting coverage instrumentation would be the right next step.
But for the purposes of delving more into structured input generation/fuzzing, let’s talk about what we could do if we had to fuzz blindly.
In this case, the fuzzer should be able to detect issues, but without coverage feedback it will struggle to generate interesting and different JSON inputs. But since we know how the rules for generating JSON (we have a grammar), we can use grammar-based generation!
Generating structured inputs with a grammar and Grammarinator#
In programming, a grammar defines how inputs must be structured to be valid for a given language (specified for the grammar).
Let’s skip the discussion on grammars and just focus on what’s important for fuzzing: we can use a grammar like a decision tree to randomly generate valid inputs!
The railroad diagrams like we saw earlier now become a choose-your-own-adventure for input creation!

There are at several tools you could use to produce inputs from a grammar, but today we’ll just look at one: grammarinator.
The most straightforward way to use something like Grammarinator is to generate a barrel of inputs to use as a starting corpus for our existing fuzzer given an existing grammar specifications:
# Install deps
pip install grammarinator
# Download json grammar
wget https://raw.githubusercontent.com/antlr/grammars-v4/refs/heads/master/json/JSON.g4
# Create Generator from grammar
mkdir json_model
grammarinator-process JSON.g4 --language py --out json_model/
# Create sample inputs
grammarinator-generate \
--max-depth 10 \
-n 10000 \
-o json_corpus/input_%d.json \
--random-seed 0 \
--sys-path . \
json_model.JSONGenerator.JSONGenerator
For JSON this generated a whole lot of small duplicate inputs, so plan to generate a lot of inputs and then dedupe them by hash.
While this isn’t fast by fuzzing standards, it does yield a reasonably diverse set of inputs fairly easily, like the handful shown below:
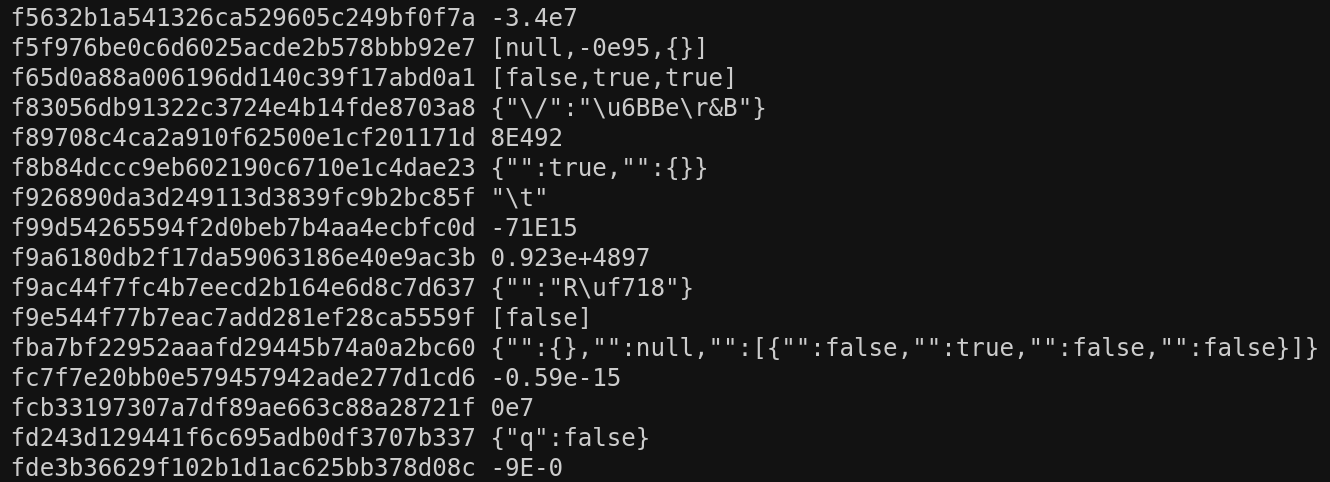
Passing these inputs as the corpus to our differential fuzzer will at least give it a better starting place.
While Atheris won’t do “grammar-aware” mutations that parse an input into a tree and make smart valid mutations, its standard strategies can still mutate and recombine inputs in interesting ways (see the papers for Gramatron and Grammarinator for details on mutations based on grammars).
Without coverage instrumentation, you can’t see the differential fuzzer make progress and you might just be wasting time… so the next step should really be getting that working.
Keep in mind when using grammars that actual implementations often support a more than just what’s in the specification, and JSON issues have been found where inputs that should not have been accepted actually were… fitting in that right side of our bug Venn diagram:
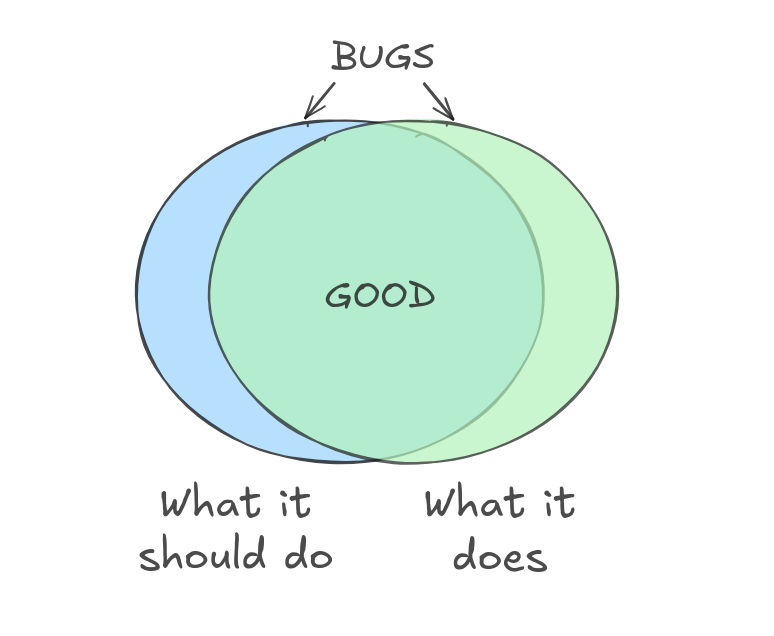
So while our grammar-based generation may not be a game changer on our own, it can be a cheap and easy way to get some varied and valid inputs for our corpus when setting out to fuzz a target that takes structured input.
Many targets, many approaches#
Long post, but we covered how something simple like JSON can end up having quite an interesting number of wrinkles, as well as showing several ways to fuzz targets that take structured inputs such as JSON:
FuzzedDataProviderand fully programmatic generation- Hypothesis as a framework for concise input generation
- Grammar-based input generation
We also went into depth about how we need to consider the true target of our fuzzing and what approaches are going to be most likely to find the bugs we want to find.
This was an interesting way for me to try out a few different approaches focused on Python, and hopefully you enjoyed it and were inspired by some of the odd bugs and issues we saw along the way.
If you liked this post, keep up with my work on the socials and let me know what you like!
No matter what’s going on around you, always keep learning, building, and growing…