
If there’s one tool I like to use to shake some bugs loose fast, it’s fuzz testing. And luckily for Python users, getting started with fuzzing is pretty easy with Atheris.
After exploring using it on one of my own Python projects, I discovered there’s not a whole lot written about Atheris… and just wanted to chip in and share a few things I found useful.
Fuzz testing is a super deep topic that we couldn’t possibly cover in a single post, so this will be part of a series on fuzzing with Atheris. This post focuses on the basics and just getting Atheris up and running.
What is Atheris?#
Atheris is a fuzzer built by Google to make fuzzing on Python as simple as possible. It’s pip-installable, provides flexible input generation, and doesn’t require much code to start using, as we’ll see.
If you’re not familiar with fuzz testing (aka “fuzzing”), it’s basically randomized negative testing. And most modern fuzzers like Atheris are coverage-guided, which means they intelligently try to exercise different functionality.
Think of this as the flip-side of unit tests:
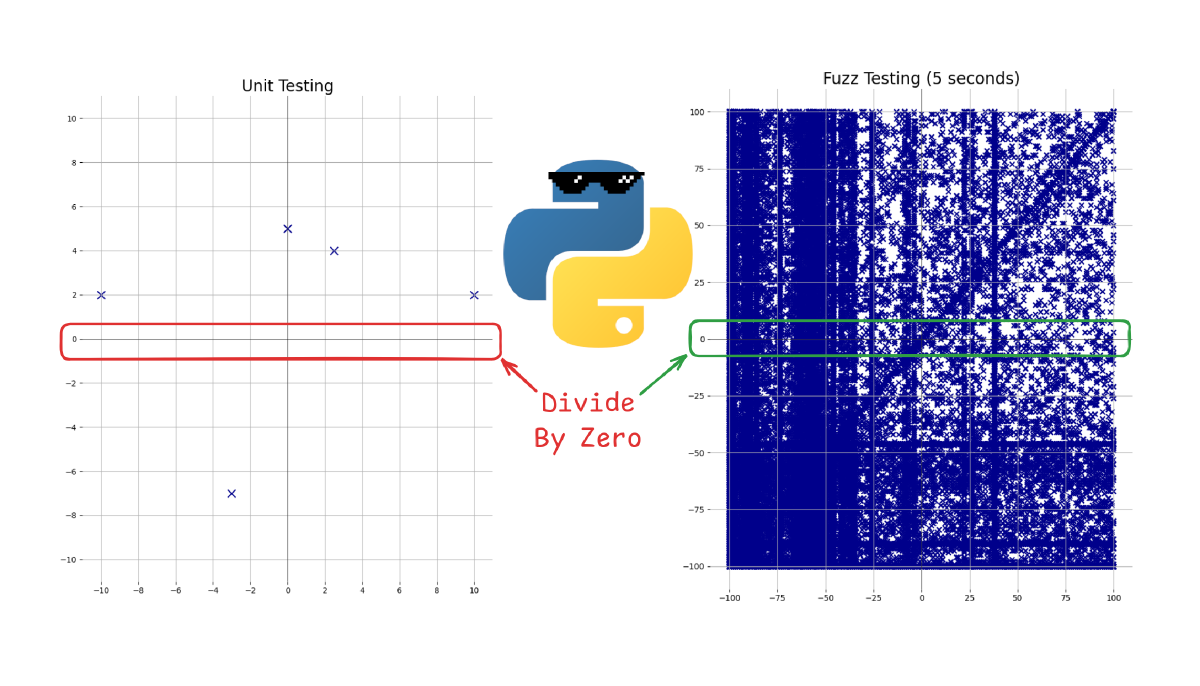
Unit tests: a few test cases to confirm the code does what it’s supposed to Fuzz testing: as torrent of randomized test cases, primarily to make sure things don’t go off the rails
If we were to graph the inputs of each method for something multiplication that takes two numbers, the difference looks like this:

And this only shows inputs from the first 5 seconds of fuzzing, which generated just under a MILLION inputs running in a VM on my laptop.
Numbers aren’t everything though, and you might think “surely the unit tests are enough and most of those inputs are redundant”…
But if you were testing division instead of a multiplication it would make a difference because of that one small difference in behavior…

Fuzzing helps us find and deal with those little details that are easy to forget about.
Why use fuzz testing in Python?#
Fuzz testing is helpful in general because programmers tend to focus on the “happy path”, and testing all the error cases can become cumbersome.
While Python programmers don’t have to worry as much about memory corruption ruining their day, there’s still a lot to be said for knowing that a piece of code handles all kinds of unexpected inputs.
For Python this usually means understanding that your code does the right thing even for “pathological” inputs or edge cases, usually in the form of throwing the right exception or returning the right value.
And with Atheris, we can pretty quickly hook up inputs and fuzz arbitrary Python code.
Getting started with Atheris#
In order to fuzz a target function, we just need to write a fuzz harness; a bit of code that takes an input and passes it into the target.
Let’s use the example of fuzzing a function that evaluates an arithmetic expression like "1 + 1" and returns the answer.
The first step is understanding the target’s interface, what types of arguments it takes and what it returns.
def evaluate_expression(expr: str) -> float:
Then we make a function that creates an input of the right type and passes it into the target, catching any exceptions we expect and asserting the type of the return value.
def TestOneInput(data: bytes):
expr = get_input(bytes)
try:
result = evaluate_expression(expr)
assert isinstance(result, float)
except ValueError:
pass
Since expr is a string, in this case we could just use the raw bytes of the input for get_input, but if we did we’d eventually find some string encoding issues that aren’t meaningful.
Using Atheris’s FuzzedDataProvider#
Instead it’s better to use Atheris’s FuzzedDataProvider to create inputs of the appropriate type from the raw input, like so:
def get_input(data: bytes) -> str:
"""Create an input of the right type from the data"""
fdp = atheris.FuzzedDataProvider(data)
max_len = 20
# get a "normal" Unicode string
return = fdp.ConsumeUnicodeNoSurrogates(max_len)
FuzzedDataProvider lets you easily create different data types depending on what your target needs:
# Produce inputs like (x, y)
def get_input(data: bytes) -> Tuple[int, int]:
fdp = atheris.FuzzedDataProvider(data)
return fdp.ConsumeIntInRange(-100, 100), fdp.ConsumeIntInRange(-100, 100)
# Produce inputs like: ['red', 'blue', 'green']
def get_input(data: bytes):
fdp = atheris.FuzzedDataProvider(data)
colors = ['yellow', 'red', 'blue', 'green']
seq = []
sequence_len = fdp.ConsumeIntInRange(1, 18)
for i in range(sequence_len):
seq.append(fdp.PickValueInList(colors))
return seq
Check out the FuzzedDataProvider section of the README for more ideas on the building blocks for making inputs.
The last thing we need to do is add a part at the top that imports the target function and instruments it with Atheris, and also a part at the bottom that tells Atheris to continuously create new inputs to fuzz the target until the target crashes or we stop it with CTRL+C.
# eval_harness.py
import atheris
# Import target function
with atheris.instrument_imports():
from target.evaluate import evaluate_expression
def get_input(data: bytes) -> str:
"""Create an input of the right type from the data"""
fdp = atheris.FuzzedDataProvider(data)
max_len = 20
return fdp.ConsumeUnicodeNoSurrogates(max_len)
def TestOneInput(data: bytes) -> None:
"""Run an input through the target function"""
expr = get_input(data)
try:
result = evaluate_expression(expr)
assert isinstance(result, float)
except ValueError as e:
pass
if __name__ == "__main__":
import sys
atheris.Setup(sys.argv, TestOneInput)
atheris.Fuzz()
Our first fuzzing run#
The only pre-requisites to run this are to do pip install atheris and to have a function at the target location, in this case evaluate_expression in target/evaluate.py.
Now we can just run the harness as a script with python eval_harness.py and start to see a bunch of output.
I used some LLM-generated code as the target function, and in less than a second of running it finds an input that causes an uncaught divide-by-zero, as shown at the end of the output:
=== Uncaught Python exception: ===
ZeroDivisionError: float division by zero
Traceback (most recent call last):
File "/home/user/atheris-intro/eval_harness.py", line 21, in TestOneInput
result = evaluate_expression(expr)
File "/home/user/atheris-intro/target/evaluate.py", line 90, in evaluate_expression
tokens = tokenize(expr)
File "/home/user/atheris-intro/target/evaluate.py", line 82, in evaluate_rpn
elif token == '/':
ZeroDivisionError: float division by zero
==177798== ERROR: libFuzzer: fuzz target exited
SUMMARY: libFuzzer: fuzz target exited
MS: 1 ChangeASCIIInt-; base unit: cb67e1c2ab1762ad5fa42d08b878c6a127db4594
0x1,0x31,0x2f,0x30,
\0011/0
artifact_prefix='./'; Test unit written to ./crash-c4afca34a047a4ad6fd6a4b3d9ec2ad257f4ff68
Base64: ATEvMA==
Atheris, like its predecessor libFuzzer, will stop as soon as a “crashing input” is found so you can stop and fix the bug, but let’s stop a moment to familiarize ourselves with the output (which is the same as libFuzzer).
Atheris/libFuzzer output explained#
The output can be a lot to understand at first, so let’s start at the top and understand what it’s telling us.

We see a line about the instrumentation, and that’s a good sign. If we forget to instrument our imports, the output would look like this:

After the instrumentation the next interesting things are the update lines (starting with INITED on down).
These indicate when the fuzzer updates it’s overall state, which is an indication of progress. There’s a lot of information in each line (so make your terminal wide enough), but let’s look at an example of output from about a second into a fuzzing run.

I’ll just call out the important bits highlighted by arrows going left to right
- Iteration count: how many inputs have been run so far
- Update reason: Most commonly this is one of three things:
NEW: new behavior/coverage encounteredREDUCE: was able to reduce the size of an input while maintaining coverage (boring)pulse: Periodic updates at exponentially decreasing intervals
- corp: The number of files in the corpus and combined size (more later on this)
- execs/s: Number of inputs being tested per second (zero for the first second or two)
Alright, now let’s go back to look at that crash!
Fuzzing to find inputs, crashes, and a test corpus#
So our “crash” is really just a divide-by-zero exception, but the terminology of crashes and inputs still works because an unhandled exception will unexpectedly stop the program.
If you noticed in the output after the crash, Atheris saved the input to a file, which makes addressing this issue much faster!
Reproducing a crash and fixing it#
Atheris works just like libFuzzer in that it allows us to replay a single file as input by passing it as a command-line argument:
python eval_harness.py crash-c4afca34a047a4ad6fd6a4b3d9ec2ad257f4ff68
This gives us output that we can use to find exactly where the Exception came from:
=== Uncaught Python exception: ===
ZeroDivisionError: float division by zero
Traceback (most recent call last):
File "/home/user/arith-fuzz/eval_harness.py", line 22, in TestOneInput
result = evaluate_expression(expr)
File "/home/user/arith-fuzz/target/evaluate.py", line 92, in evaluate_expression
tokens = tokenize(expr)
File "/home/user/arith-fuzz/target/evaluate.py", line 84, in evaluate_rpn
elif token == '/':
ZeroDivisionError: float division by zero
In this case we’re not going to fix the issue, we just want to handle this exception (since throwing an exception in the case of division by zero is what we want).
We can make a quick edit to handle that exception type and replay the input:
try:
result = evaluate_expression(expr)
assert isinstance(result, float)
except ValueError as e:
pass
except ZeroDivisionError as e:
pass
INFO: Instrumenting target
INFO: Instrumenting target.evaluate
INFO: Using built-in libfuzzer
WARNING: Failed to find function "__sanitizer_acquire_crash_state".
WARNING: Failed to find function "__sanitizer_print_stack_trace".
WARNING: Failed to find function "__sanitizer_set_death_callback".
INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 3226624814
eval_harness.py: Running 1 inputs 1 time(s) each.
Running: crash-c4afca34a047a4ad6fd6a4b3d9ec2ad257f4ff68
Executed crash-c4afca34a047a4ad6fd6a4b3d9ec2ad257f4ff68 in 0 ms
***
*** NOTE: fuzzing was not performed, you have only
*** executed the target code on a fixed set of inputs.
***
And as expected, no crash is reported.
Pretty useful to be able to find and fix that quickly, given how little work went into writing that harness.
But after handling that exception type, the fuzzer just runs forever… which is really the first goal of fuzzing: ensuring the target doesn’t crash when fed random inputs.
But finding crashes is interesting and important, fuzzing is perhaps more useful in finding regressions.
Generating a test corpus#
So our second goal is to maintain a set of inputs that exercise different code paths, especially ones that caused crashes in the past.
In this case we didn’t fuzz for long at all, but it’s best practice to save all of the interesting inputs so we have test corpus for the future, which is what Atheris does if you give it a path to a directory:
mkdir corpus
python eval_harness.py corpus
# Let it run for a bit, then do CTRL+C
We can then use the corpus to easily replay all the inputs later, presumably once the code changes.
After about a minute, the fuzzer had saved 104 inputs in my corpus directory.
The decision of when to stop fuzzing can have a lot of factors, but the big thing to remember is that you get diminishing returns over time in a logarithmic fashion, and you can see when an input discovers new behavior by the NEW lines that are printed.

So once you’ve fuzzed for a bit and see a lot less lines reporting NEW and a lot more reporting REDUCE or pulse, then you know you probably got most of the behavior.
Since the pulse lines are shown in exponentially increasing intervals, if you see pulse three times in a row, you can safely stop.

For corpus size, the precise number of inputs isn’t really important as long as it’s more than a couple. The number of inputs in the corpus is more of a reflection of the complexity of the target code than anything else.
The important part is now we have an input that previously caused a crash and 104 more that we can use for testing future versions of our code.
Fuzzing for security bugs#
A quick note on security and “crashes”: for regular Python code, crashes are likely just going to be unexpected exceptions; security problems are unlikely to be discovered by a simple fuzzing harness like this.
For example, if the implementation of evaluate_expression just passed the input to eval under the hood, that could be a serious vulnerability, but Atheris will not be able to detect this as an issue because it can’t tell the difference between intended functionality and an unexpected bug.
We’ll talk more about this topic in a future post, but the upshot is that to catch security bugs you typically need a “bug oracle”, some way of programmatically detecting a problem and reporting it.
But for now we can at least do a little more to understand what our corpus actually got us.
Understand fuzzing progress with line coverage#
The easiest way to get feedback on what the fuzzer did for us is to get line coverage of the target function.
We could try to measure coverage off the original harness, but due to some of the peculiarities of how Atheris runs and potential interactions with coverage recording, it’s simpler to just make a separate script to run a target file or corpus directory.
The only parts that really change is that we directly pass a file to be the input source and we don’t instrument the import:
# run_corpus.py
import atheris
import os
import sys
# No instrumentation on this import
from target.evaluate import evaluate_expression
def get_input(data: bytes) -> str:
fdp = atheris.FuzzedDataProvider(data)
max_len = 20
return fdp.ConsumeUnicodeNoSurrogates(max_len)
def RunInputFromFile(file_path: str):
"""Read the input from the file specified and run the target"""
with open(file_path, 'rb') as f:
data = f.read()
expr = get_input(data)
try:
result = evaluate_expression(expr)
except ValueError:
pass
except ZeroDivisionError:
pass
def main(corpus: str):
"""Take a directory OR single file as input and feed it to the target"""
if os.path.isdir(corpus):
for filename in os.listdir(corpus):
file_path = os.path.join(corpus, filename)
RunInputFromFile(file_path)
print(f'[*] Ran {len(os.listdir(corpus))} inputs from "{corpus}"')
elif os.path.isfile(corpus):
one_file = corpus
RunInputFromFile(one_file)
print(f'[*] Ran single input "{one_file}"')
if __name__ == "__main__":
if len(sys.argv) != 2:
print("USAGE: python run_corpus.py CORPUS")
exit(-1)
# Not using Atheris here
corpus = sys.argv[1]
main(corpus)
With this script, we can install coverage.py with pip install coverage, and then we can run it and get coverage information super fast:
# Run under coverage
$ coverage run run_corpus.py corpus/
[*] Ran 100 inputs from "corpus/"
# Summarize what lines got covered
$ coverage report
Name Stmts Miss Cover
----------------------------------------
run_corpus.py 34 8 76% # Don't care about this
target/__init__.py 1 0 100%
target/evaluate.py 75 1 99% # This is the target file
----------------------------------------
TOTAL 110 9 92%
# Make an HTML report
$ coverage html
And if we want to see the one(!) line that escaped our fuzzer coverage, a quick look at that HTML report shows it’s not super interesting.

100% line coverage doesn’t mean that nothing can go wrong, but it is a quick and easy way to tell that our fuzzer seems to be exercising the code well.
For a deeper discussion on different types of coverage information and applications, check out my previous series on coverage.
But that’s enough for one post.
We’ve only begun to fuzz#
We packed a lot into that tiny little harness, but we covered a lot of ground:
- How to harness a target function with Atheris
- How to generate structured data with
FuzzedDataProvider - How to read Atheris/libFuzzer output
- How to find, reproduce, and fix crashes
- How to build a test corpus with fuzzing
- How to measure the coverage of fuzzing
Hopefully this gives a taste of how easy Atheris is to use, and is a little taste of the really deep world of fuzzing.
I’m sure some you eagle-eyed readers noticed that we didn’t do any checks on the correctness of the implementation of the target function, other checking the correct type was returned.
While having the right type might be good enough for a Rust dev, we’re going to want to do more and try out some advanced techniques while we’re at it.
Stay tuned for more, because next time we’ll be diving into property testing, differential fuzzing, and other fuzzing tricks.