

When it comes to flame graphs, there seems to be two groups of people: those who think they’re awesome, and those who somewhat abashedly admit they don’t know how to use them.
Since I’ve been focused on visuals for code, I can’t leave out flame graphs for several reasons: A) they look really cool and B) they are one of the most helpful visualizations out there, and C) you can generate them for a shockingly wide number of use cases.
We’ll focus on concrete examples for Python (GitHub repo), but the lessons apply to any flame graph. And once you know their secrets, you’ll find more places to use them.
How to generate a flame graph for Python#
Currently the best and most portable way I know to get a flame graph specifically for Python code is:
# Install tools to translate cProfile output and generate the flame graph
pip install -U flameprof
git clone --depth=1 https://github.com/brendangregg/FlameGraph
# Profile your python script (this method doesn't require changes) & make SVG
python -m cProfile -o output.prof myscript.py
flameprof output.prof --format log > output.folded
./FlameGraph/flamegraph.pl output.folded > mygraph.svg
# Open the SVG in a browser for the interactive experience
We’ll show how to use the more-generic Linux perf in the profiling tools section, but this should be enough to get us going.
Quick process rundown#
Brendan Gregg’s original flamegraph tool was built to process files in three stages: perf files as input, a “folded stacks” intermediate format, and SVG files as output.
Here we’re using Python’s cProfile instead of Linux’s perf, and cProfile’s output needs to be translated to the collapsed stack format.
So we use flameprof to do the translation and flamegraph make the final result, or to use a picture:
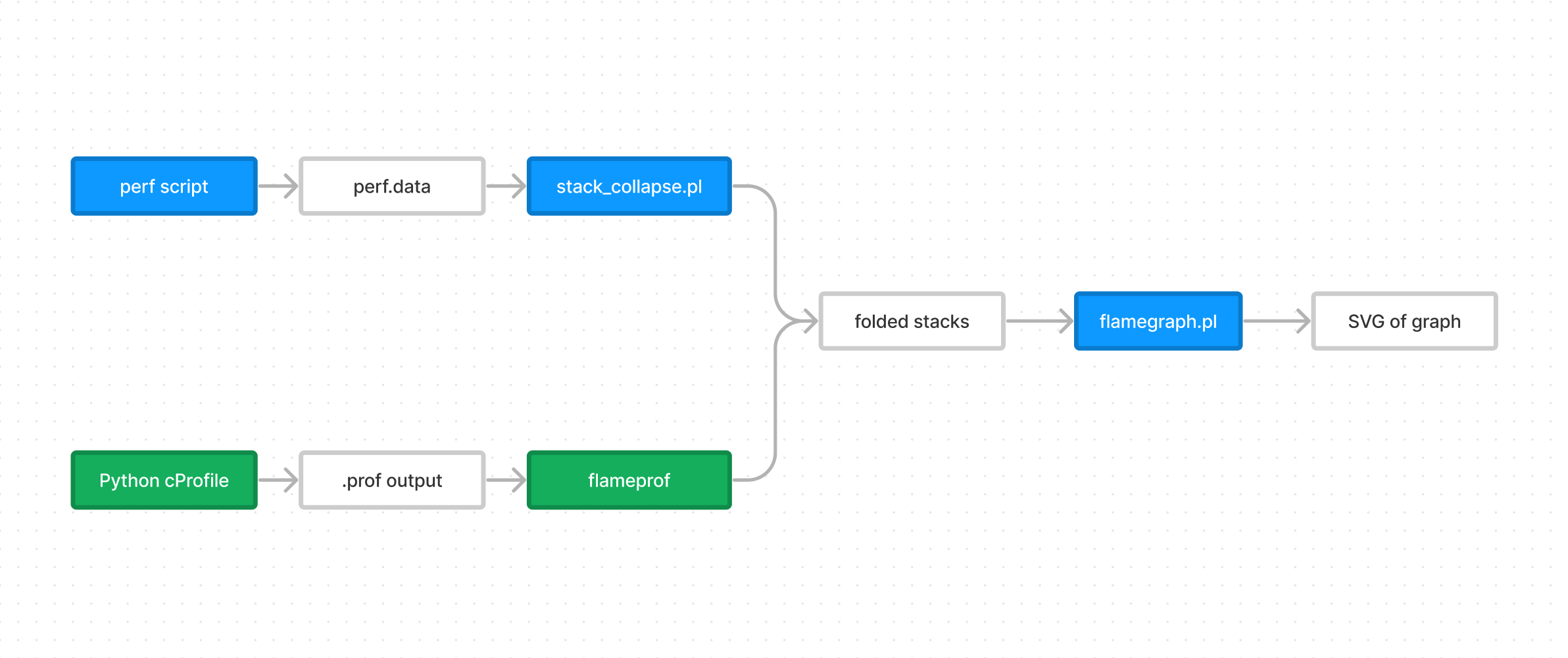
We can use other tools for collecting data and producing flame graphs, but beware that not all implementations are created equal (more on that later).
How to read a flame graph#
The most important thing to understand about reading flame graphs is that the X-axis shows relative duration: a box’s width indicates the percentage of total duration spent in that function.
So the graph is not a timeline, it’s a summary of what happened over the entire recorded duration, whether it was 10 seconds or 10 milliseconds.
So if we see a flame graph like this:

We know that we must have been specifically profiling main() because it takes up 100% of the graph width.
We can also see that on top of main, we have child_b spent more time than child_a, and the fact that each child function is stacked on top of main means that main called the two child functions.
So the y-axis shows stack depth for all functions called during the recording, where vertical stacks show all the recorded call stacks (e.g. main called child_a which called grandchild_c which called sleep).
Looking at the very top of the flame graph, we see calls to sleep() with no boxes above it.
An exposed top edge of a box means that the duration was spent in that function and not in any child functions.
And if we look at the call graph for the example, we can see how the flame graph relates.
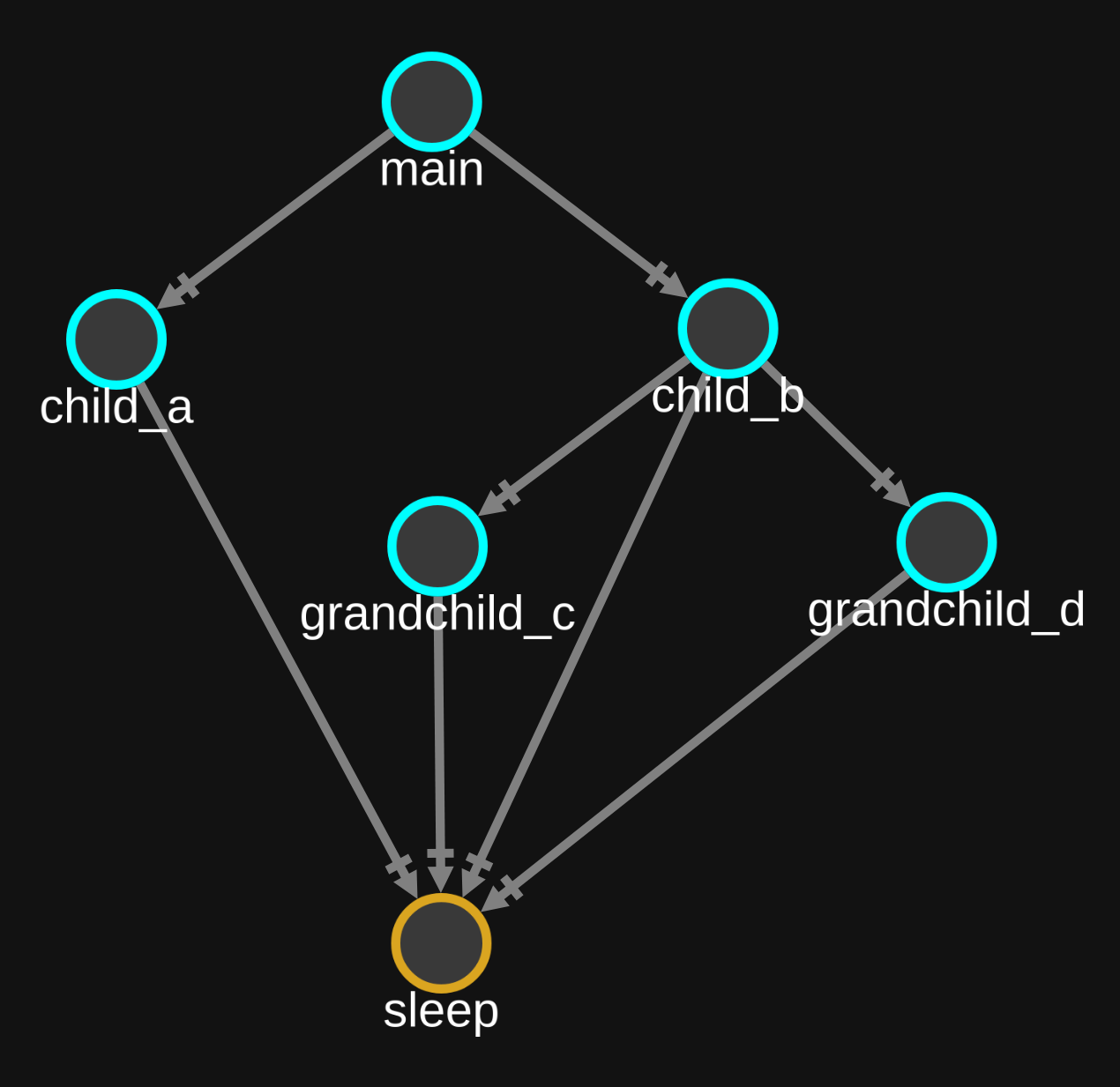
The static call graph shows what could happen, and the flame graph shows what did happen in this particular case, as well as the ordering of and the relative amount of time spent in each node.
Details of flame graphs explained#
There’s actually a lot of cool details packed into this visualization that are worth knowing because they either 1) let you utilize non-obvious functionality or 2) generate interesting or more-helpful variations on the basic flame graph.
Functionality for power users#
We learned a lot about our example script just by looking at the flame graph, but if we look at the code itself there are a couple of things to notice:
from time import sleep
import cProfile
def main():
child_a()
child_a()
child_b()
def child_a():
print('In A')
sleep(1)
def child_b():
print('In B')
sleep(1)
grandchild_c()
grandchild_d()
def grandchild_c():
print('In C')
sleep(1)
def grandchild_d():
print('In D')
sleep(1)
if __name__ == '__main__':
profiler = cProfile.Profile()
profiler.enable()
main()
profiler.disable()
profiler.dump_stats('output.prof')
# Less flexible, but also works:
#cProfile.run('main()', 'output.prof')
First is that this time we inserted the use of cProfile into the code, so running this script automatically produces an profiling file.
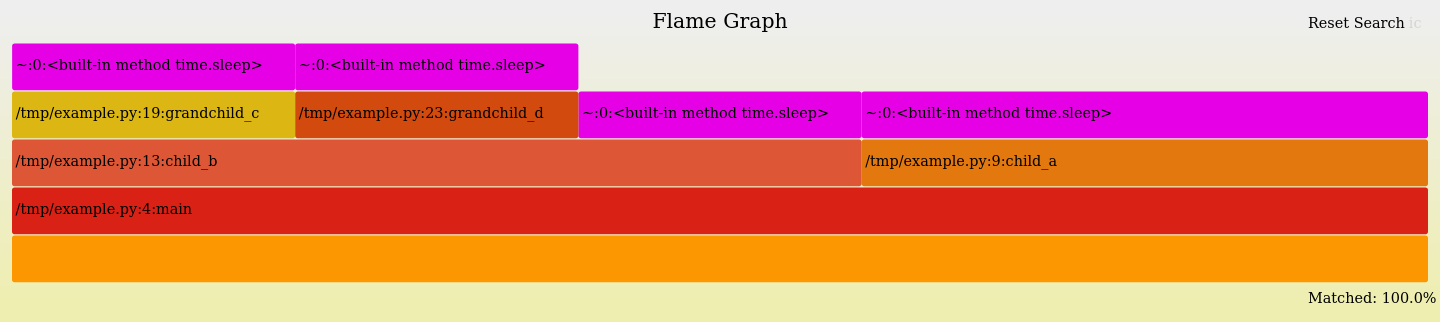
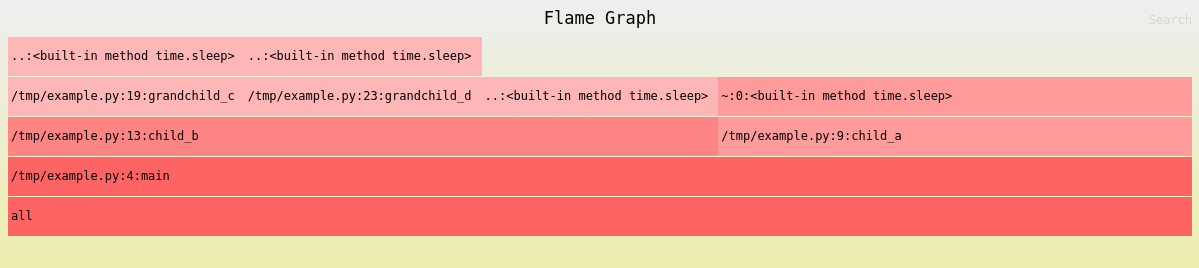
The second is to notice that the call pattern doesn’t seem fully represented in the flame graph (shown again below): child_a is called twice but only has one box in the graph, while sleep is called 4 times and has four boxes. What gives?
This happens because there are four unique call stacks that reach sleep, while child_a is called from the same parent call stack every time.
The standard flame graph summarizes durations based on call stacks, so just keep it in mind because the number of times a function is called isn’t shown and we don’t want to try to visually sum box widths.
Instead let’s use the search functionality (click in the upper right-hand corner to get a prompt) to highlight all of the places a function is called and list the total percentage of time taken by boxes matching the pattern you type (Matched 100.0% in the bottom right of the screenshot below):
We can also click on any box to zoom in on it, and which will cause total percentage matching the pattern to update for the new zoomed-in duration:

Scalable and interactive… not bad for a single self-contained file, eh?
If you want to try the interactivity out yourself, open the link to the SVG we’ve been talking about so far in a new tab and play around with it.
Flame graph variations#
Something it usually takes people a while to notice or ask about with flame graphs is “how does it pick colors?”
Usually this is triggered the first time you get one with particularly bad aesthetics, and the answer is that they’re picked randomly each time they’re generated! …by default anyway.
We can override it with --consistent, which will generate a palette.map file that will be reused on successive runs (and we can manually tweak the file).
This also make all of the boxes for the same function appear the same color, like in the sleep() boxes below:
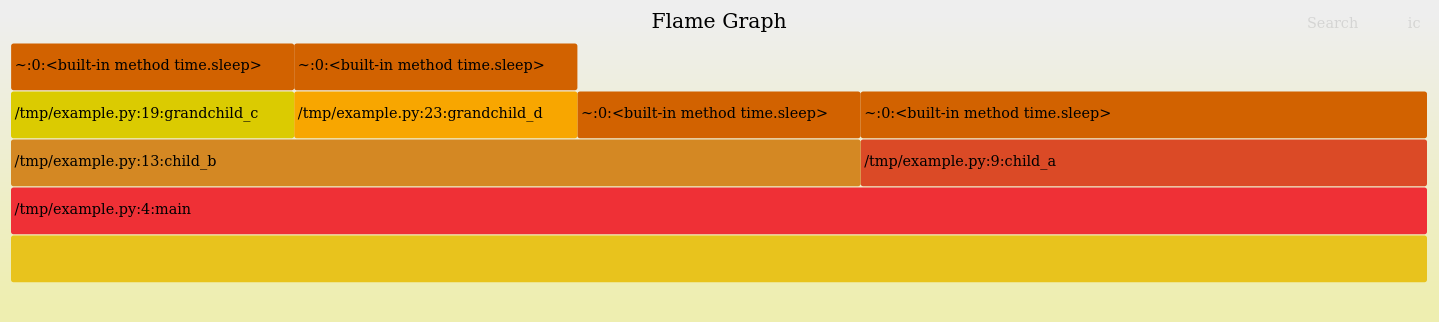
This seems like a bit of a missed opportunity since colors can really help in visuals and could be used for other things.
For example there’s some nice flame graph tooling in Rust called inferno that has a few slick improvements, including a --colordiffusion option to show more intense colors for boxes with greater duration:
A more complex example will help show what this is supposed to look like. While I like the idea, it’s a teensy bit redundant since it’s hard to see subtle color differences and it mirrors what width already indicates (and maybe requires a different background color).
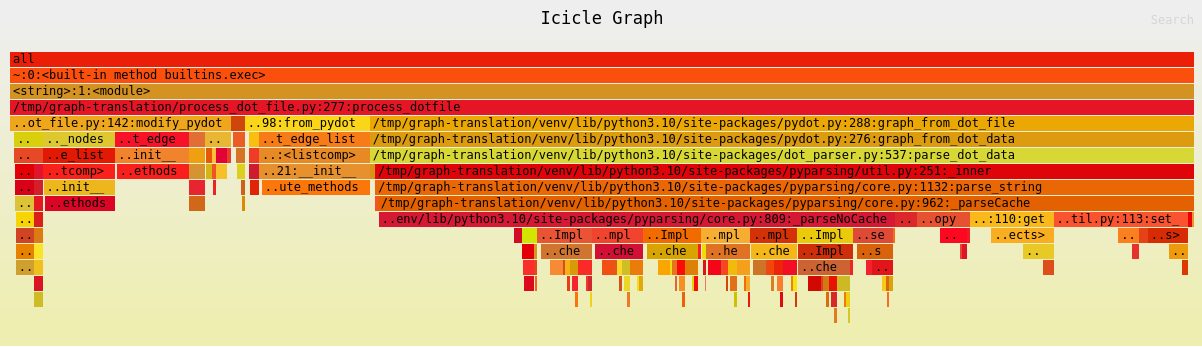
Another variation you might hear about is “icicle graphs”, which is just an upside-down flame graph (starts at top and grows downwards).
We can get graphs like this with --inverted if you prefer them that way… the screenshot below is a another more realistic example to give a better flavor of it:
And while the --reverse option sounds similar, it actually produces a result that’s way more different than just flipping the y-axis.
A “reversed” flame graph tries to merge different paths to functions together, which is very helpful for seeing when the same function is appearing across multiple call stacks, like how in our example sleep is where all the time is actually spent:
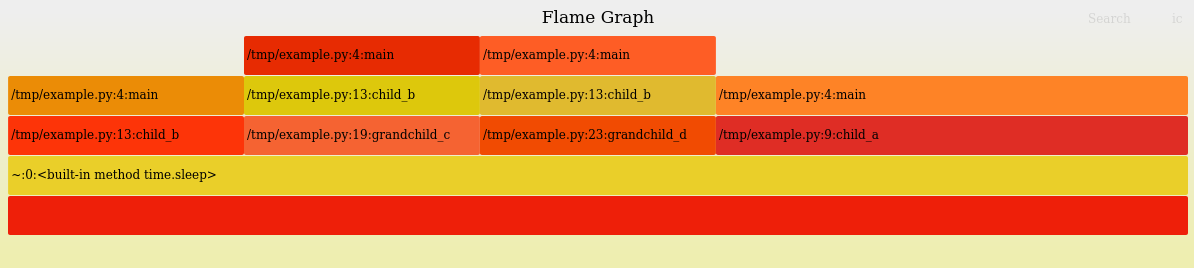
Which is helpful when I’m looking for functions to optimize that might be called in many places.
The only other options that I’ve put to use in this post are --height to make certain smaller graphs more readable on first glance and inferno’s --stroke-color to add thin lines to increase separation between blocks.
Whew, I think that’s enough for now. Hopefully these variations inspire some new ideas about flame graphs and show some of the detail and flexibility of the format.
Examples of using a flame graph#
Sometimes I feel like explanations don’t really seem real without concrete examples, so let’s walk through two quick examples based on common performance questions that are related but slightly different:
- What part of the code is taking the longest?
- What in my code can I optimize for the biggest payoff?
What’s taking so long?#
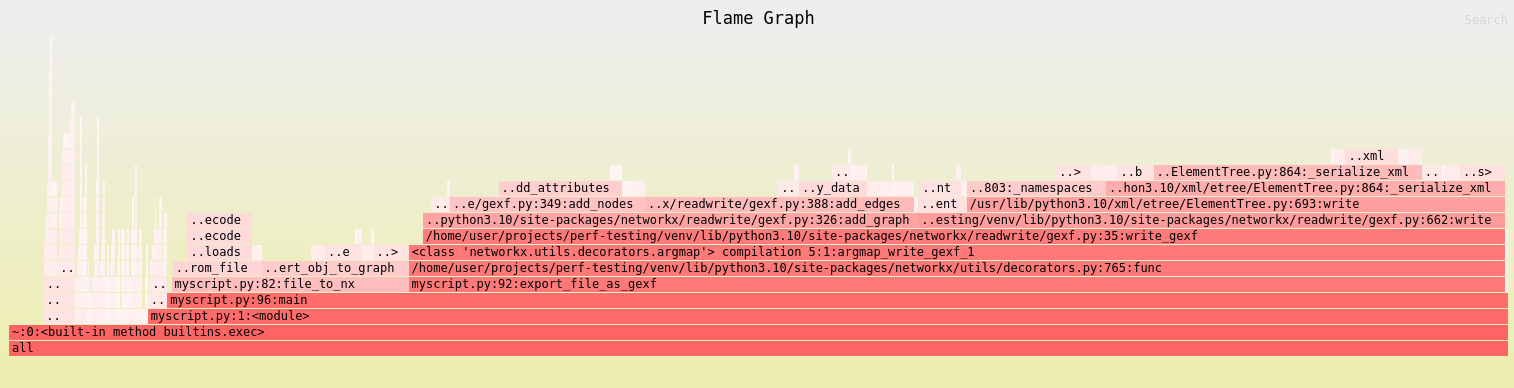
I recently wrote a script for translating one graph format to another, and when I ran it on a decently-sized graph, I was surprised at how long the script took to execute.
Somewhat puzzled, I quickly busted out a flame graph using the steps from the beginning of the article and started poking around using the zoom and search:

You might be able to notice that I split the task into two parts: parse the original format into a networkx Graph object in the file_to_nx function, and then use networkx to export the graph to a well-known format in the export_file_as_gexf function.
But the real insight from this recording is that I quickly realized that the bulk of the time was spent in networkx, specifically in its code that exported the graph (the search also shows it’s also used during import too).
For this example, I wasn’t going to rewrite that code to make it go any faster, so I decided to just live with the slow performance for large graphs.
Anticlimactic, but true.
How can I make this faster?#
In last year’s Advent of Code programming challenge, there was one problem in particular where I could tell my approach was only a couple of optimizations away from running fast enough to work.
Of course I was doing just enough to finish, and I had ideas about where to optimize, but no hard data. Luckily I could profile my code based on the smaller sample input and get a good idea of where I might want to focus.
Flame graphs to the rescue! (Interactive SVG)
{kind=link}
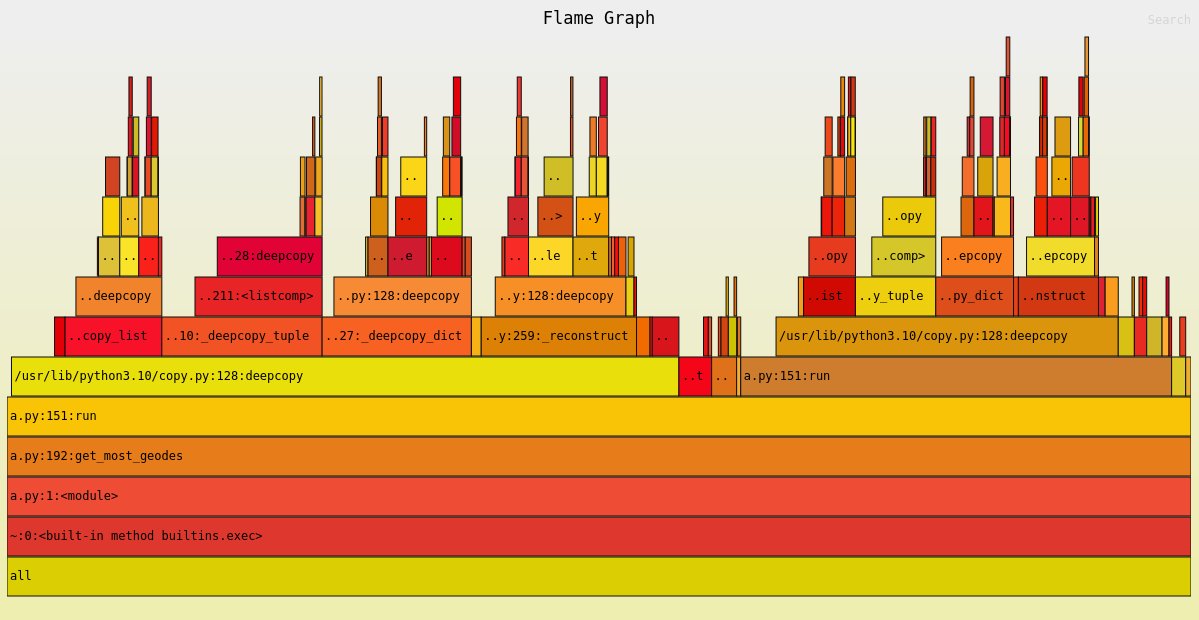
My first thought was to find where in my code CPU time was being spent (shown by an exposed top edge), OR the first call to functions in libraries external to my code.
Interestingly, the majority of the time is being spent in deepcopy, which I only called in one line, but naturally that line was hit for every possible state being searched.
Looking at the flame graph I could see how much time was spent in things like _deepcopy_list, _deepcopy_dict, and <listcomp>, which made me look at what exactly would be copied in the state:
class State():
def __init__(self, blueprint):
self.blueprint = blueprint
self.resources = (0, 0, 0, 0)
self.robots = (1, 0, 0, 0)
self.minute = 1
There’s only one member that isn’t a simple object, blueprint, which was a list of lists.
And looking at how that was used, I realized I only needed one instance of it and didn’t need to copy it into each new state.
So just to see if I could get a cheap win, I refactored it to make blueprint a global instead of a class member so it doesn’t get copied… and I couldn’t believe the result:
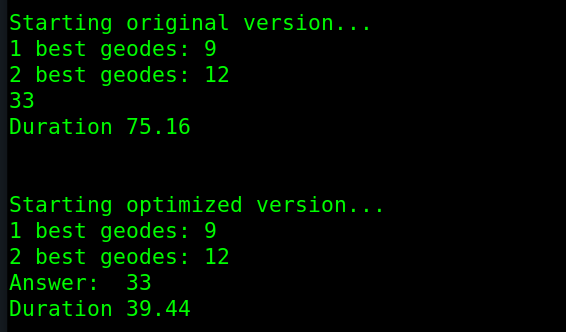
I repeated each 3 more times just to convince myself it wasn’t a statistical anomaly, but it was true.
One silly guess of an optimization, when guided by a flame graph, sped up my code by almost a factor of 2.
Yes, it was a speedup because I hadn’t realized I’d done something silly while in a rush… but that probably never happens to production code, right?
Recommendations on profiling/viewer tools and alternatives#
There’s really three groups of tools to touch on really quickly: profilers, generators, and viewers.
Profiling tools#
The original source of performance data for flame graphs was Linux’s perf, which is extremely powerful and you can read more about in a lot of places (I recommend Julia Evans and Brendan Gregg).
For now I’ll just say that it works really well for compiled code, but not so well for interpreted languages like Python unless they have mechanisms to expose their internals (which Java does and Python is doing soon in the upcoming 3.12 release).
python example.py &
PYTHON_PID=$!
# Use perf to profile the Python process
sudo perf record -F max -p $PYTHON_PID -g -- sleep 10
# Generate FlameGraph from perf.data
sudo perf script | \
~/tools/flamegraph/stackcollapse-perf.pl | \
~/tools/flamegraph/flamegraph.pl > flamegraph.svg
We can see that we do get information between all the [unknown], but nothing about the code from the script that ran, which is why we use cProfile.
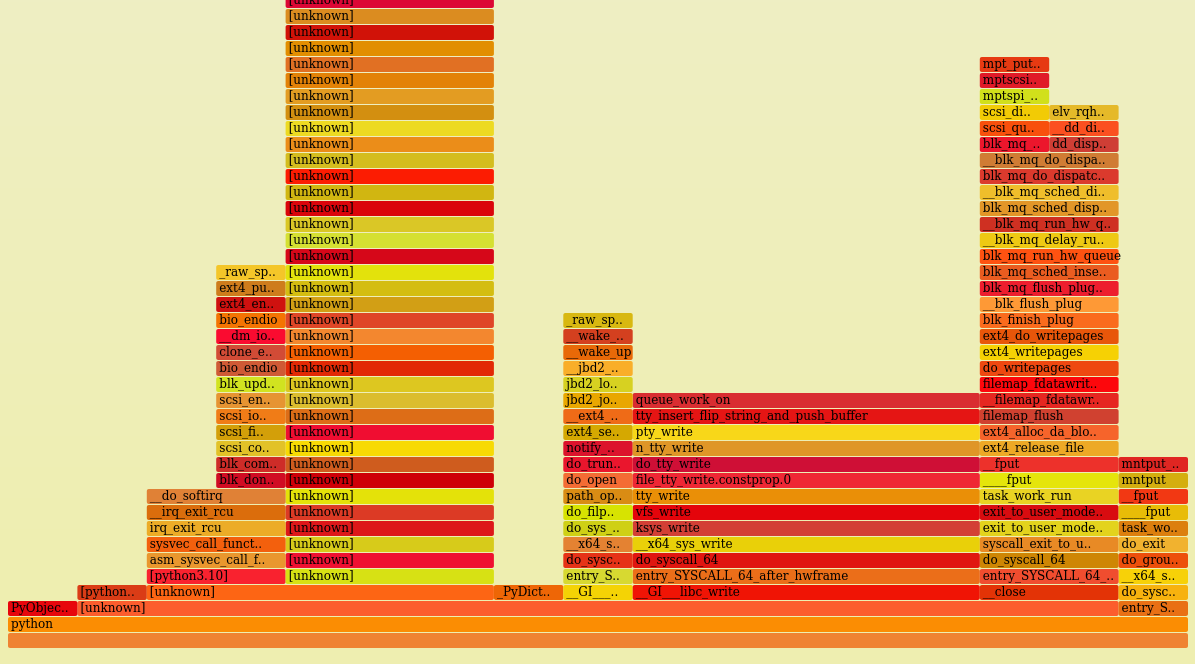
cProfile is also a deterministic profiler, which means it works by instrumenting the target so it can take precise measurements at the cost of slowing down the target and introducing some bias, whereas perf is a “sampling” profiler.
A statistical or sampling profiler just takes samples of the current state of the target at a high frequency, which doesn’t slow down the target but has its own trade offs.
If you want a sampling profiler for Python, I like py-spy, which can generate its own flame graphs or be used with another tool:
py-spy record -o pyspy_flamegraph.svg python example.py
# OR
py-spy record -f raw -o raw.stacks python example.py && \
cat raw.stacks | inferno-flamegraph > raw.svg
Generator Tools#
We talked about the original pipeline at the beginning of the article, where the FlameGraph tools originally processed perf data into the eventual SVG.
A lot of tools (like py-spy) have tried to cut out the middleman and make their own, but I like sticking to the original pipeline idea because it gives more flexibility and options for tweaking the output.
The only difference is that I like to use inferno because of some of their options, but it’s just a matter of personal preference.
Viewer Tools#
There are a lot of other options other than making flame graph SVGs and viewing them in the browser, but honestly the options I’ve looked at haven’t inspired me to want to change.
But if you want to play with stuff other than the class SVG+browser combo, here’s three alternate viewers that might interest you:
- speedscope: Looks similar to browser dev tools,
py-spycan export to a format that can be explored locally or with their webapp - flamegraph-d3: A beautiful rendering, but requires manual work to get up and running
- hotspot: a GUI for Linux Perf data, includes a couple of nice timeline and tabular features
There’s also some visualizations that can be alternatives for flamegraphs, like sunbursts or treemaps, or call graphs.
But honestly, I think flame graphs can’t be beat for this kind of analysis.
Keepers of the flame#
So we’ve seen a whole lot of graphs and managed to cover a lot on how to make, read, and customize flame graphs.
These graphs are a perfect example of how visualizations can help us deal with the amount and complexity of data related to software. The design of them just has a lot of really smart details, so hats off to Brendan Gregg for inventing and popularizing them.
I hope this has given you either a powerful new capability or at least a little more value out of a classic tool in the toolkit.
If you enjoyed this jaunt into the depths of visual exploration, check out my other posts on this blog or on various interwebs.