
If I could use one word to describe code coverage, it would be “underrated”.
Code coverage is a powerful tool that can help in a number of workflows, and while it is an extra step to gather it, the information it yields can unlock important insights about code. Whether you’re trying to improve your test coverage to ensure your code does what it is supposed to, or you’re just trying to see what’s going on in some legacy code (or even a binary that you’re reversing), code coverage helps you see what’s happening, which is why I’m a fan of it.
Once you’ve gotten used to having it, you’ll want to have it on all your projects. But to get the most out of it, it helps to understand what it is and how to get it. Once we have that down, we’ll talk about how it’s commonly used as well as the powerful ways it could be used.
This is the first in a three-part series, so feel free to skip ahead if you’re already a coverage veteran.
- Part 1: Code coverage explained (this post)
- Part 2: 5 ways to get coverage from a binary
- Part 3: Automated coverage analysis techniques
What is code coverage, anyway?#
The first question is what kind of coverage information we’re looking for, because there’s multiple types.
Generally speaking, coverage information just records what code was executed when the target program ran, but what you might not realize is that there’s a spectrum of options when it comes to code coverage, because most tools just support one, maybe two kinds.
On one end of the spectrum you have path coverage, with line coverage on the other. The tradeoff is between more detailed information and the increased overhead in terms of the space the data takes up and added time overhead it costs to record it.

Path coverage#
Path coverage includes the most information, recording instruction (or basic block) the target ran in, and is most often used in full-system tracing. Since many instructions will be executed over and over again, this takes up a lot of space and usually slows down the target significantly during recording; for this reason it’s not commonly used in most development workflows.

Line or block coverage#
Line/block coverage is on the other end of the spectrum, and it just tells you which lines of code executed without indicating the order of execution or number of times it was executed. When you have source, you can get line coverage or statement coverage (mostly the same but some older schemes may not be able to differentiate between multiple statements on the same line).
If you don’t have source, the best you can do is basic block coverage (just called “block coverage”). It’s the same idea as line coverage, but you have to disassemble either statically or on-the-fly to determine block boundaries. If you’ve got debug symbols, you can even take block coverage and map it back to the source code for line coverage information. The terms block, statement, and line coverage are largely equivalent, so I prefer to use the term “block coverage” unless it would be confusing to not say “line coverage.”

Note that the diagram above illustrates that block coverage isn’t guaranteed to be in order of execution.
Branch or edge coverage#
Naturally branch coverage (also called “edge coverage”) is somewhere in between, recording the transitions between basic blocks. Similar to block coverage, it does not indicate order or number of times a branch is executed, though seeing if back-edges get taken on loops and recording transitions between functions does gives some very useful information that block coverage does not. Fuzz testing will commonly use branch coverage with hit counts of some type because it is a good tradeoff between granularity of information and the speed and size requirements to record it (this was one of the most important contributions of AFL).

There’s a couple more exotic coverage metrics, but these are the common types.
Code coverage tools for C/C++#
Most tools focus on line and branch coverage, because the end result that most people want to see is a color-coded report of their source code that shows what code got executed and what didn’t.
I’m not going to get into the debate of what percentage of coverage is enough coverage (it depends on what the project is), instead I’ll just say that whether you’re reading, writing, optimizing, or debugging code, this is a pretty helpful visual.
If you’re using an interpreted language, this is easier because you typically have the source and there’s often packages or language features to produce coverage–so let’s focus on compiled code and start with C/C++.
I think it helps to see two different approaches to understand how there’s different ways of getting to the end result, so let’s quickly walk through how to get coverage reports from two of the most common compilers: gcc and clang.
Coverage reports: gcc, gcov, lcov, and gcovr#
Getting coverage using the venerable gcc is pretty straightforward, just compile with --coverage and the object files that are output will be instrumented to output gcc’s coverage data.
Under the hood this is the same as -fprofile-arcs -ftest-coverage while compiling and -lgcov when linking, but the important thing to notice is that when you build with --coverage you see some new files:
$ gcc --coverage hello.c -o hello
$ ls
hello hello.c hello.gcno test
$ file hello.gcno
hello.gcno: GCC gcno coverage (-ftest-coverage), version B.3
And then when you run the instrumented target, you’ll see more files appear:
$ ./hello
Hello world!
$ ls
hello hello.c hello.gcda hello.gcno test
$ file hello.gcda
hello.gcda: GCC gcda coverage (-fprofile-arcs), version B.3
If you experiment by moving the executable to a different directory, you’ll notice that it writes the coverage files to a different path. One of the major assumptions that a lot of these tools make is that you’re collecting coverage on the same system you build the target on, and that you have the source at the same location. There are certainly times where that’s not the case, so just be aware of that.
At this point we’ve collected the coverage, now let’s make a report. We’ll demonstrate three similar tools gcov, lcov, and gcovr so you can see that they all do basically the same thing and you can use whatever tool you prefer. The instructions assume you’ve installed them via package manager (apt install gcov lcov gcovr) by building from source.
Of the three, gcov is the simplest and is built to output text reports, so it’s more meant for quick terminal work than building pretty reports. Using the -t and -k flags (gcov docs) will print to stdout and color the outputs, like shown below:

lcov was built to be a more visually appealing front-end for gcov, and it produces pretty HTML reports where you can browse directories and files. It works in two steps, producing an intermediate coverage file and then producing the report.
$ lcov -c -d . -o hello.info
# Turns the .gcda file(s) into the output file
$ genhtml -o report hello.info
# This produces an HTML report in the specified dir
$ open report/index.html
The report allows you to browse by directories and files and drill down into the source for each as shown below.

lcov is suitable for working with modern projects, but newer coverage tools have since come out that run faster, look slightly nicer, and are written in languages other than Perl. gcovr is one such utility; it does basically the same thing as lcov but a bit better (gcovr docs).
$ gcovr --html-details gcovr.html
$ ls
gcovr.css gcovr.hello.c.0fba0eab2c0a1c0fdea332d6efaeae74.html
gcovr.html hello hello.c hello.gcda hello.gcno lcov
$ open gcovr.html
This produces a report that looks pretty similar…

And that’s good enough to get the job done with gcc, so now let’s see how clang differs…
Coverage reports with clang and llvm-cov#
As you might imagine, it’s a very similar process to get line coverage using clang, but they ask for different flags and their coverage information is stored in different places and formats.
Let’s use the same example as before and this time build with -fprofile-instr-generate and -fcoverage-mapping foo.cc.
$ clang -fprofile-instr-generate -fcoverage-mapping hello.c -o hello
$ ls
hello hello.c
$ ./hello
Hello world!
$ ls
default.profraw hello hello.c
$ file default.profraw
default.profraw: LLVM raw profile data, version 8
So we see the coverage file has a default name, which can be adjusted by setting an environment variable: LLVM_PROFILE_FILE="hello.%p.profraw" ./hello would work in this case. Now we have to use the llvm tools from the llvm package (llvm-profdata docs) to process the coverage data and produce a nice report like we saw with gcc.
# First convert the "raw" coverage into the "indexed" profdata
$ llvm-profdata merge -sparse default.profraw -o hello.profdata
$ file hello.profdata
hello.profdata: LLVM indexed profile data, version 7
# Produce the HTML report using the binary & profdata
$ llvm-cov show -format html -o report \
--instr-profile hello.profdata hello
$ open report/index.html
You can use llvm-cov show and llvm-cov report to output command line data similar to gcov (llvm-cov docs), but most of the time the HTML report is the most useful. You can also use llvm-cov export to export to either JSON or lcov formats, which just goes to show that’s all pretty much the same data.

Three code coverage perspectives#
Ok, so yeah… you use typically it to get a visual on what code got covered.
From a developer’s point of view, the most common coverage workflow is checking unit test coverage, because you want to identify which code didn’t get covered by your tests (which means you won’t catch it if that code or your assumptions break in the future). Naturally you also want to see the coverage from any integration and end-to-end tests.
I do want to separately call out fuzz testing though, because unit tests are more about confirming the behaviors you expect and only address the cases you choose to test. Fuzz testing is helpful because it both discovers many behaviors, and is an effective way to discover unexpected behaviors. Best practice would be to ensure you have fuzz coverage for any code that parses untrusted input or highly complex function.
But ultimately as a developer, the primary benefit of coverage is that it helps you find any outdated or bad code hiding in the corners.

For reverse engineers, coverage data is helpful because it highlights what code is actually executing when the target runs. This either saves you a bunch of time because you can focus on that active code, or helps you understand what conditions need to be different to exercise different parts of the code. You can even do this if you don’t have source…

Lastly, from a hacker’s point of view, looking at coverage from tests and just running the target under normal circumstances gives an idea of what the developer expects to happen. It’s a common axiom: code that isn’t tested is more likely to have bugs (especially if we’re talking fuzz testing), and that’s a great place to start looking if you’re auditing a codebase.
So far we’ve discussed coverage data in isolation, but what happens if we start to combine coverage data (the simplest dynamic analysis) with some of the other kinds of analyses? Very cool stuff, and there’s a handful of tools to use coverage data as a bridge–which is exactly what we’ll be talking about in the third post in this series.
If you write high-assurance code or are trusting code with your money or your life, having high coverage is definitely the best practice, but it’s not perfect because…
Code coverage’s dirty secret#
Having 100% code coverage does not mean that code has no vulnerabilities.
There, I said it.
I’m not the first to say it either, there’s some classic information on that particular fact. SQLite has had 100% test coverage since 2010 and there have still been a decent number of bugs found in it.
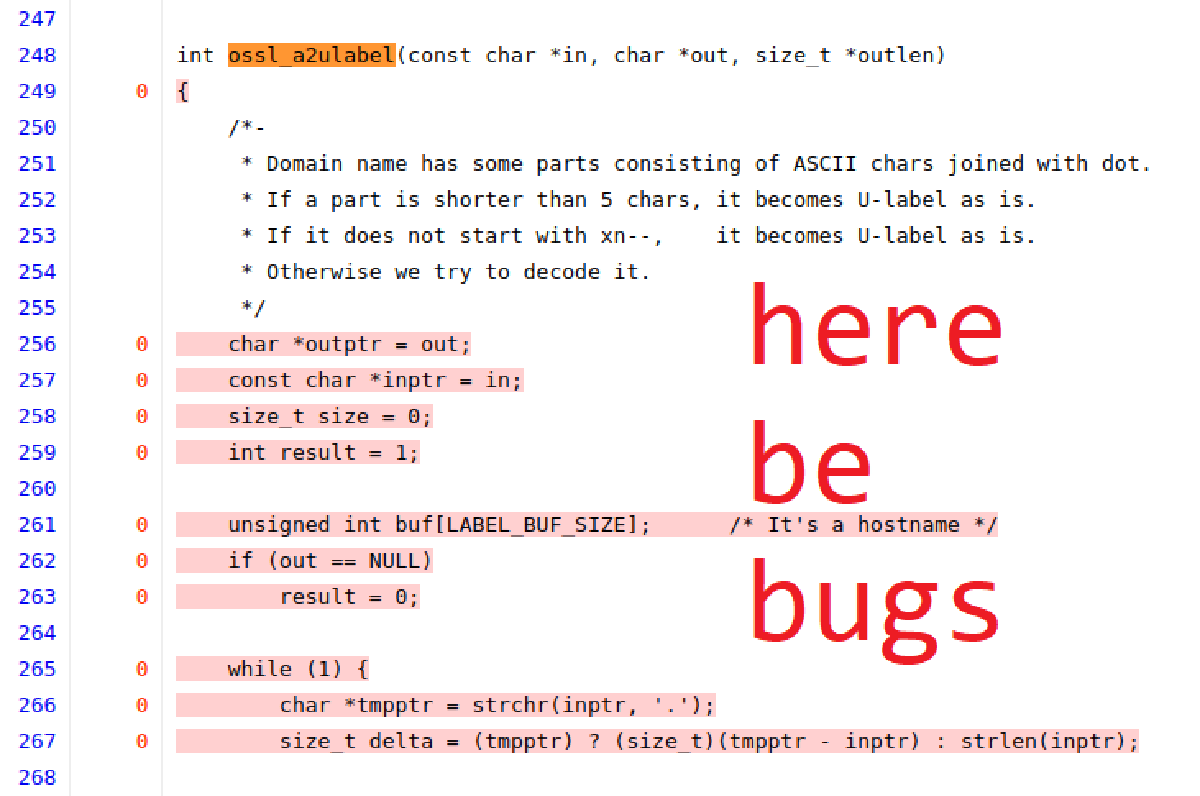
Why is this the case? Simply put: code coverage only reflects the content of one register, the instruction pointer. This is only one dimension in the astronomical state space for a program, but instead of talking big numbers and exponents, let’s just use a simple example:
int lets_divide(int x, int y) {
return x / y;
}
We can easily see that this function contains one line. And there’s a bug in it. It doesn’t matter how many times you cover that line, there’s only one value for one of the variables that triggers the bug. Easy to miss, even with 100% code coverage.
Now, this bug might be guarded against by code outside the function, like shown below. Having 100% code coverage helps here because you’d know you have a test case that would reach the bug if you ever removed that check.
int use_input(int a, int b) {
if (b == 0)
return 0; // if not covered by tests...
return lets_divide(a, b); // bug could emerge undetected later
}
This is terrible practice of course, because it assumes you’ve got the same check on all the callsites, and invites failure down the road if use_input ever changes… you should just put the safety checks in the function that needs them, not depend on every caller.
So yes, code coverage is not data coverage. It doesn’t always stop things like use-after-free, divide-by-zero, integer overflow, command injections, and other bugs, but that’s not its purpose. Its purpose is to help people see and understand what code actually ran.
Coverage: slept on more than beds#
So that wraps up the first installment in our 3-part series on code coverage. In part 2 we’ll check out interesting ways to get coverage beyond using a compiler, and in part 3 we’ll dive into advanced coverage techniques and combining analyses.
Has code coverage ever saved you from a stupid bug or helped you find one? I’d love to hear about it; send me a note on Twitter to get in touch!